▲ 지금까지의 알파고와는 완전히 다른 '알파고 제로(AlphaGo Zero)'. 알파고 제로가 바둑 입문을 하는 것부터 역대 최강이 되기까지의 과정을 보고 있으면 바둑이론의 진화를 한눈에 보는 듯한 느낌이 든다. [이미지 | 구글]
인간의 기보를 전혀 학습하지 않은 알파고 새 버전 ‘알파고 제로(AlphaGo Zero)’가 베일을 벗고 세상을 놀라게 하고 있다.
지금까지의 알파고는 인공신경망 속에서 지도학습(supervised learning)이라는 인간기보 학습을 거쳤지만 알파고 제로는 이 과정을 거치지 않았다. 오직 스스로 대국하면서 강화학습(reinforcement learning)으로만 실력을 키웠다. 바둑의 기본 규칙을 제외하고, 알파고 제로의 학습에 인간의 개입이 없는 것이다.
이렇게 ‘독학한’ 알파고 제로는 지금까지 가장 강하다고 알려져 왔던 ‘알파고 마스터(AlphaGo Master)’버전을 압도적으로 이기는 것으로 나타나 충격을 준다.
알파고 제로는 각각 같은 연산력(TPU 4대를 갖춘 싱글머신)에 제한시간 2시간의 조건으로 알파고 마스터와 100판을 겨뤄 89승11패 했다. 약 90%의 승률이다. 알파고 마스터는 올 초 인간 고수들을 상대로 60전 전승을 거둔 뒤 5월 세계 최강 커제 9단을 3-0으로 제압했던 버전인데 알파고 제로 앞에서는 상대도 안 되는 셈이다. (알파고 제로는, 이세돌 9단과 겨뤘던 알파고 버전에는 100전 100승을 기록했다.)
알파고 제로 알고리즘과 테스트 결과 등을 담은 논문 ‘인간 지식 없이 바둑을 마스터하다(Mastering the game of Go without human knowledge)’가 19일(한국시각) 과학학술지 네이처(Nature)에 게재됐다. 데미스 하사비스 딥마인드 창업자 겸 최고경영자를 포함한 알파고 제작사 구글 딥마인드 연구원 17명이 공동저자다.
무(無)에서 시작한 알파고의 진화속도는 놀라웠다
알파고 제로는 그야말로 아무데나 두는(완벽한 무작위 착수) 것으로부터 시작한 뒤 바둑의 개념(포석, 맥, 패, 끝내기, 수상전, 선수, 모양, 세력, 집 등)을 정교하게 이해하는 단계로 나아갈 때까지, 매우 빠른 속도로 진보하였다.
아무런 사전 지식 없이 오직 바둑 규칙만 입력된 알파고 제로는 훈련을 시작하면서 18급만도 못한 바둑을 보여줬다. '1의1'에도 거침없이 뒀다.
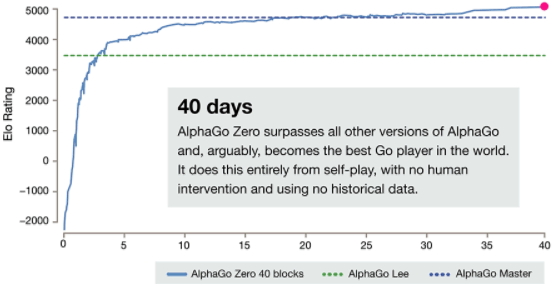
▲ 기보를 한 번도 보지 않았다. 그저 자기 자신과 바둑을 두면서 역대 최강의 바둑 실력을 갖출 때까지 알파고 제로에게 필요한 세월은 불과 40일이었다. [이미지 | 구글]
3시간이 지나자 바둑에 갓 입문한 사람의 수준이 되었다. 오직 상대 돌을 잡으러 다니는 데 혈안이 된 모습을 보였다.
19시간이 경과하면서 기본기가 갖춰지고 점차 사활·세력·집과 같은 바둑전략의 요소를 이해하기 시작했다.
3일이 지나면서 ‘알파고 리(AlphaGo Lee,이세돌 9단을 이긴 알파고 버전을 지칭)’수준을 넘어서기 시작했다.
▼ 훈련시작 뒤 3시간이 지난 시점의 알파고 제로의 셀프대국 - 마치 바둑교실 입문반 어린이들의 대국을 보는 것 같다. 돌을 잡는 데만 신경이 쏠려 있고 단수를 치면 잇지 않고 되단수를 쳐 오히려 자신이 잡히는 경우도 많이 보인다. 패에 대해서도 아직은 잘 이해하지 못하는 단계다.
▼ 훈련시작 뒤 19시간이 지난 시점의 알파고 제로의 셀프대국. - 알파고는 드디어 사활 개념을 이해하기 시작한다. 흑7과 흑19는 알파고 마스터의 기보에서 자주 보였던 일명 묻지마 삼삼(early 3-3 invasion)'이어서 우리에게 익숙하다. 단, 흑13이나 27을 이 시점에서 두는 것은 아까울 수 있다. 훗날 기분 좋을 A의 들여다봄 찬스가 줄어들기 때문이다. 13에 두는 이유는 역으로 상대가 그 자리에 두면 선수로 당하기 때문이다. 그럼에도 타이밍을 잘 보아야 한다.
▼ 훈련시작 뒤 70시간이 지난 시점의 알파고 제로의 셀프대국. 이 시점에서 알파고는 인간 수준을 뛰어넘는다.
인간 이론에서 변의 흑을 강화시켜주는 백6은 부분적으로 악수다. 흑23부터 펼쳐지는 우상공방은 예측이 쉽지 않다.
이후 좌하귀 변화는 알파고 제로들끼리 만들어 낸 신 정석. 흑63의 끊음이 최초로 시도됐다. 백은 지금처럼 64로 두어 왼쪽 한점을 잡거나 67의 자리에 응수할 수 있다. 흑63의 응수타진에 백은 주위 배석에 유의하며 행마하여야 한다.
21일이 경과하자 알파고 마스터와 비슷한 수준에 이르렀다.
40일 동안 약 3천만 대국을 훈련한 뒤엔 알파고 마스터를 크게 이겼다. 이 단계가 되자 알파고 제로는 기존 정석을 선호하지 않는 경향을 보였고 사람 수준에서 예측하기 어려운 참신한 변화가 증가했다.
인간의 기보를 안 거쳤더니 왜 더 강해졌을까
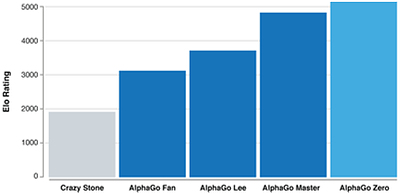
알파고 제로는 Elo레이팅 5,185점을 기록하고 있다. 알파고 마스터 4,858점, 알파고 리 3,739점, 알파고 판(판후이) 3,144점 순이다.
알파고 제로가 인간의 기보로 학습한 기존 알파고를 압도하는 이유를 놓고 연구진은 “사람이 그간 쌓아온 바둑에 대한 접근법과는 질적으로 다른 전략을 알파고 제로가 깨친 것으로 보인다.”고 짚었다.
▲ 알파고 제로, 그리고 기존 알파고 버전들의 Elo레이팅 비교. [이미지 | 구글]
※대진표 상하좌우 이동하며 볼수 있습니다.
논문의 공동저자 데이비드 실버(David Siver)는 “인간 지식의 한계에 더 이상 얽매이지 않기 때문.”이라고 강조했다.
이 밖에 정책망(policy network, 다음 수를 선택) 가치망(value network, 승자를 예측)으로 알려진 두 개의 신경망을 하나로 통합하여 훈련과 평가에 효율성을 높인 것도 이유의 하나로 꼽힌다.
●알파고 제로 ○알피고 리(이세돌을 이긴 알파고 버전)
225수 흑불계승
●알파고 제로 ○알파고 마스터(커제를 이긴 알파고 버전)
265수 흑불계승
●알파고 제로 ○알파고 제로
228수 백불계승
국가대표팀 “알파고 제로의 기보, 해석 어려워”
알파고 제로의 기보를 접한 국가대표상비군들은,
“인간의 기보를 전혀 보지 않고 훈련했는데도 인간의 바둑처럼 틀이 잡히는 변천 과정이 신기하다.”
“신선하다. 하지만 이전 알파고 마스터 버전의 셀프대국 55국이 워낙 파격적이었기에 충격파는 그렇게까지 크지 않다.”
“알파고 마스터의 바둑과 비교해 보면 오히려 알파고 제로가 더 인간과 비슷해 보이기도 한다.” 등의 반응을 보였다.
한편 “우리가 알파고 제로가 얼마나 강한지 평가하는 것은 마치 18급이 정상급 프로기사들을 비교하는 것이나 마찬가지.”라며 “알파고 제로의 사고방식이 도움을 주는 부분도 어느 정도 있지만 대부분은 해석조차 쉽지 않다.”는 목소리도 나왔다.
불과 3년전만해도 인공지능 바둑 기사 뜨면 뭐 100년이 걸려도 못이긴다고
거의 댓글 달더니만(물론 프로기사들은 10~20년으로 봤지만)이제는 6점으로도
못이긴다고 다 달겨드네..댓글 수준 너무낮아 차마 눈뜨고 못볼지경..ㅎㅎ
바둑, 컴퓨터, 과학에 대한 이해가 18급도 안돼는 양반들이 말은 제일 많어..
달밤에사활|2017-10-22 오후 8:16:00|동감 1
인간 지식 없이 바둑을 마스터하다 - 알고리즘은 누가 썼나? 바둑 전혀 모르는 프로그래머
가 쓴 건 아닐텐데.
40일 동안 약 3천만 판의 대국 -
40일 x 24시간 = 960 시간
960시간 x 60분 = 57,600 분
57600분 x 60초 = 3,456,000 초
3천만 판을 3백만 초에 두려면 1초에 10판의 바둑을 두었다는 얘기다. 그 와중에 세계 최
강의 실력이 되었다니 놀랍다. 컴퓨터의 사양, 제한시간, 컴퓨터를 몇 대나 쓴 건가 이런 것
이 궁금하다.
알파고 은퇴한다더니 컴백하려나?
과거초보|2017-10-20 오후 7:02:00|동감 0
알파고 이길 기사는 김구라 9단 뿐이다. 알파고, 너 그렇게 두는게 아냐 하면서 혼내며 두면
이긴다.
흑백마스터|2017-10-20 오후 5:26:00|동감 0
알파고 제로의 바둑은 해석하기조차 어려워보이네. 인간의 정석은 거들떠도 안본다니. 한마디로 현재 프로들이 만든 정석은 정수가 아니라는 얘기네.
장위동박|2017-10-20 오후 3:17:00|동감 0
지금까지는 그냥 그럭저럭 넘어간다지만, 내년에는 알파고 제로 보다도 100배이상 더 성능좋은 알파고가 나온다니 큰일이다.(앞으로 10년후에는 기원에 인공지능 로봇들만 모여앉아 바둑을 두겠네, 이세돌 9단과 두었던 알파고 리는 시니어 리그에..)
돌파1|2017-10-20 오후 12:08:00|동감 0
바둑은 대국 상대가 있어야하니 알파고제로가 20개가 있어서 서로 대국을 해야 40일 동안 3천만 판을 둘 수 있을 것 같은데요. 알파고 제로 2개 가지고는 40일 동안 3천만 판이 나올 수 없자나요. 여기에 대해서 기자가 취재 좀 해 주세요.
돌파1|2017-10-20 오전 8:06:00|동감 0
글쓴이 삭제
덤벙덤벙|2017-10-20 오전 7:39:00|동감 4
덜떨어진 사람들이 人間과 人工知能(A.I.)을 區別하지 못하고 興奮한다. 機械(컴퓨터)는 機械(컴퓨터)일 뿐, 東洋人들이 3,000年 동안 쌓아온 바둑의 깊이는 그나름대로 價値가 있다. 칠 때마다 홀인원, 알바트로스, 이글, 버디를 하는 골프 人工知能(A.I.)을 만든다고 하여서 努力하여 언더 파를 치는 人間과 比較할 수 없는 것과 같은 理致이다. 機械는 아무리 人間보다 나은 實力을 보이더라도 結局은 機械(컴퓨터)일 뿐이다. chilled out, please!!!
덤벙덤벙
디프마인드의 하사비스 사장같은 西洋人들이 아무리 바둑을 좋아하고 努力한다고 하여도 (죽었다 깨어나도) 東洋人들을 따라올 수 없으니 結局 알파고를 만든 것이 아닐까? A.I.에서 가장 뒤쳤던 구글이 2011년 4억 5천만 달러(5,000억원)를 주고 디프마인드를 引受함으로써 하사비스는 그 돈으로 프로그램을 開發할 수 있었는데 만약 돈이 없었다면 알파고는 아직도 日本의 딥젠고나 中國의 A.I.보다 뒤떨어질 것이다. 그러므로 西洋의 資本主義가 東洋의 精神을 (돈으로) 制壓했다고 볼 수 있다. 그런데 왜 이렇게 같은 東洋人인 韓國 사람들까지 호들갑을 떠는가? 淺薄한 世界1位 커제(柯潔)는 바둑 神이라고까지 말하면서 偶像을 崇拜하고... 덜 떨어진 中國애다. 2017-10-20 오전 7:53:00
ProblemMe
누가 덜떨어진 사람인지.... 마치 원자력 발전소가 없어야 나라가 부강한다는 원리외 꼭같네.... 2017-10-20 오전 11:47:00












 Unify
Unify

 달밤에사활
달밤에사활
